Do Offline Metrics Predict Online Performance in Recommender Systems?
In submission, 2020
Karl Krauth, Sarah Dean, Alex Zhao, Mihaela Curmei, Wenshuo Guo, Benjamin Recht, Michael I. Jordan. https://arxiv.org/pdf/2011.07931.pdf
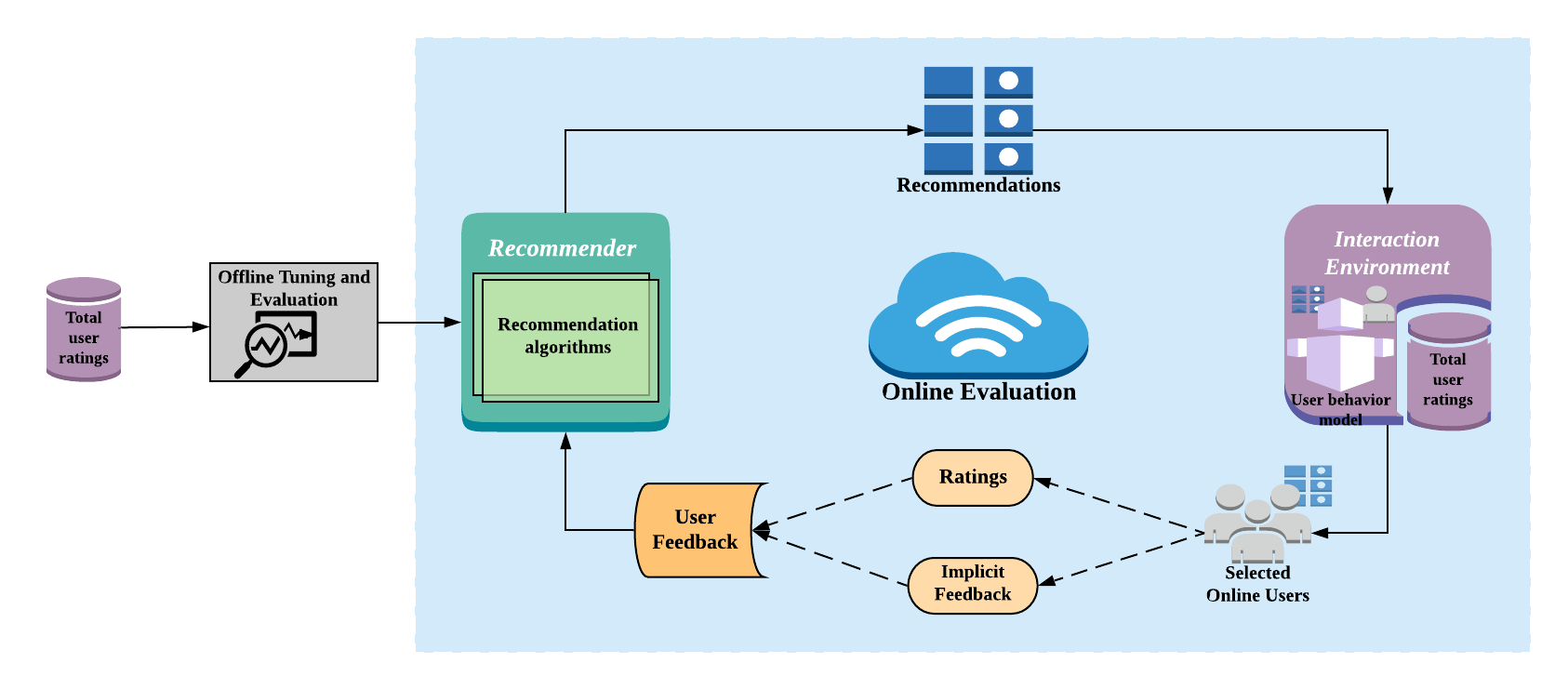
Recommender systems operate in an inherently dynamical setting. Past recommendations influence future behavior, including which data points are observed and how user preferences change. However, experimentation in production systems with real user dynamics is often infeasible and existing simulation-based approaches have limited scale. Many state-of-the-art algorithms are designed to solve supervised learning problems, and progress is judged only by offline metrics. In this work we focus on answering the question: Is offline behavior reflective of online performance?
We provide a partial affirmative answer to this question in the context of six simulated environments and eleven recommenders, including: baseline neighborhood models, battle-tested matrix factorization models, and recent deep recommender models. We observe that offline metrics are correlated with online performance over a range of environments. However, improvements in offline metrics lead to diminishing returns in online performance. Moreover, we observe performance drops when algorithms are initialized in low-data regimes, without access to enough offline training data. We study the impact of adding exploration strategies, and observe that their effectiveness, when compared to greedy recommendation, is highly dependent on the recommendation algorithm.
In sum, our results provide necessary validation for the use of offline metrics as a proxy for online performance. However, they cast doubts on the importance of focusing on small offline performance improvements, especially in high-data regimes where current algorithms already predict near optimally. Instead, we point to issues of diversity, coverage, and sampling as having potentially higher impact.